
Securing private data at scale with differentially private partition selection
We present novel algorithms to preserve user privacy in data releases, improving the state of the art in differentially private partition selection.
Large, user-based datasets are invaluable for advancing AI and machine learning models. They drive innovation that directly benefits users through improved services, more accurate predictions, and personalized experiences. Collaborating on and sharing such datasets can accelerate research, foster new applications, and contribute to the broader scientific community. However, leveraging these powerful datasets also comes with potential data privacy risks.
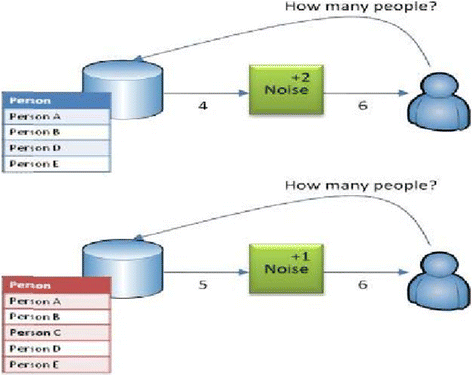
The process of identifying a specific, meaningful subset of unique items that can be shared safely from a vast collection based on how frequently or prominently they appear across many individual contributions (like finding all the common words used across a huge set of documents) is called “differentially private (DP) partition selection”. By applying differential privacy protections in partition selection, it’s possible to perform that selection in a way that prevents anyone from knowing whether any single individual’s data contributed a specific item to the final list. This is done by adding controlled noise and only selecting items that are sufficiently common even after that noise is included, ensuring individual privacy. DP is the first step in many important data science and machine learning tasks, including extracting vocabulary (or n-grams) from a large private corpus (a necessary step of many textual analysis and language modeling applications), analyzing data streams in a privacy preserving way, obtaining histograms over user data, and increasing efficiency in private model fine-tuning.
A parallel algorithm is essential for massive datasets like user queries. Instead of processing data one piece at a time (like a sequential algorithm would), a parallel algorithm breaks the problem down into many smaller parts that can be computed simultaneously across multiple processors or machines. This practice isn’t just for optimization; it’s a fundamental necessity when dealing with the scale of modern data. Parallelization allows the processing of vast amounts of information all at once, enabling researchers to handle datasets with hundreds of billions of items. With this, it’s possible to achieve robust privacy guarantees without sacrificing the utility derived from large datasets.
In our recent publication, “Scalable Private Partition Selection via Adaptive Weighting”, which appeared at ICML2025, we introduce an efficient parallel algorithm that makes it possible to apply DP partition selection to various data releases. Our algorithm provides the best results across the board among parallel algorithms and scales to datasets with hundreds of billions of items, up to three orders of magnitude larger than those analyzed by prior sequential algorithms. To encourage collaboration and innovation by the research community, we are open-sourcing DP partition selection on GitHub.
The algorithm’s operation The goal of DP partition selection is to maximize the number of unique items selected from a union of sets of data, while strictly preserving user-level DP. This means that very popular items, belonging to many users, can often be safely preserved for downstream computational tasks, whereas items belonging to only a single user would not be included. The algorithm designer must aim for an optimal privacy-utility trade-off in selecting items from the dataset while respecting the differential privacy requirement.
The standard paradigm: Weight, noise, and filter
The conventional approach to differentially private partition selection involves three core steps:
Weight: For each item, a “weight” is computed, typically representing the item’s frequency or some aggregation across users. This forms a weight histogram. A crucial privacy requirement is “low sensitivity”, meaning that the total weight contributed by any single user is bounded. In a standard non-adaptive setting, users assign weights to their items independently of what other users contribute (e.g., the Gaussian weighting baseline).
Noise: To ensure DP, random noise (e.g., Gaussian noise with a specific standard deviation) is added to each item’s computed weight. This obfuscates the exact counts, preventing an attacker from inferring an individual’s presence or data.
Filter: Finally, a threshold determined by the DP parameters is applied. Only items whose noisy weights exceed this threshold are included in the final output.
Improving utility with adaptive weighting
A limitation of the standard, non-adaptive approach is potential “wastage”. Highly popular items might receive significantly more weight than necessary to cross the privacy threshold, effectively “over-allocating” weight. This excess weight could have been more effectively used to boost items that are just below the threshold, thereby increasing the overall number of items released and improving the utility of the output.
We introduce adaptivity into the weight assignment process to address this. Unlike non-adaptive methods where each user’s contribution is independent, an adaptive design allows the weight contributed by a user to an item to consider contributions from other users. This is a delicate balance, as it must be achieved without compromising privacy or computational efficiency.
Our novel algorithm, MaxAdaptiveDegree (MAD), strategically reallocates weight. It identifies items with significant “excess weight” (far above the threshold) and reroutes some of that weight to “under-allocated” items (those just below the threshold). This adaptive reallocation ensures that more less-frequent items can cross the privacy threshold and be included in the output. Moreover, MAD maintains both the same low-sensitivity bounds and efficiency as the baseline, meaning it offers the same strong privacy guarantees and scalability in parallel processing frameworks (like MapReduce-like systems), but with strictly superior utility.
Furthermore, we extend this concept to multi-round DP partition selection frameworks. We demonstrate how to safely release intermediate noisy weight vectors between rounds. This additional information allows for even greater adaptivity, as we can reduce future weight allocations to items that previously received too much weight (and were likely to be over-allocated again) or too little weight (and were unlikely to ever cross the threshold). This further refines the weight distribution, maximizing utility without sacrificing privacy, and further increases the items in output.
Experiments
We conducted extensive experiments comparing our MAD algorithm with one or multiple iterations against scalable baselines for private partition selection.
As shown in the table below, MAD with just two iterations (column MAD2R) achieves state-of-the-art results across many datasets — often outputting significantly more items than other methods (even those using more rounds) while retaining the same privacy guarantees.
In our paper, we present theoretical results that suggest our single-round algorithm (MAD) should always outperform the single-round Gaussian weighting baseline mentioned above. Our results demonstrate that this theoretical hypothesis appears to be correct. The excellent performance of our new methods holds across a wide selection of privacy parameters and hyperparameter choices. An example in-memory implementation of our algorithm in Python is available in the open-source repo.
On the large-scale publicly-available Common Crawl dataset (comprising close to 800 billion entries), we obtained record-level DP by treating entries as “users” and the words in these entries as items. On this dataset, our two-iteration MAD algorithm output a set of items that covered 99.9% of the entries (each of which has at least one item in the output) and 97% of the database entries (corresponding to an item that is in the output) while satisfying the DP guarantee.
With just two iterations, our algorithm achieved state-of-the-art results in a wide range of parameter settings. As expected from our theoretical results, our algorithm always outperformed the baseline.
Conclusion
We introduce new methods to improve the utility-privacy trade-off in DP partition selection algorithms. Our algorithm achieves state-of-the-art results on datasets approaching a trillion entries. We hope this algorithm will help practitioners achieve higher utility across their workflows while strictly respecting user privacy.